**Background:** the authors are developing a static analysis library (or perhaps framework) called [Codex](https://codex.top/) and publishing papers on it. This post summarizes their most recent paper, which got accepted to [OOPSLA 2024](https://2024.splashcon.org/track/splash-2024-OOPSLA). The full paper and an artifact (Docker container) are both linked, and Codex is on [GitHub](https://github.com/codex-semantics-library/codex/tree/main) with a [demo](https://codex.top/papers/2024-oopsla-typedc-dependent-nominal-physical-type-system.html). Excerpt: > One of the main challenges when analyzing C programs is the representation of the memory. The paper proposes a **type system**, inspired by that of C, as the basis for this abstraction. While initial versions of this type system have been proposed in [VMCAI'22](https://codex.top/papers/2022-vcmai-lightweight-shape-analysis.html) and used in [RTAS'21](https://codex.top/papers/2021-rtas-no-crash-no-exploit.html), this paper extends it significantly with new features like support for union, parameterized, and existential types. The paper shows how to combine all these features to encode many complex low-level idioms, such as flexible array members or discriminated unions using a memory tag or bit-stealing. This makes it possible to apply Codex to challenging case studies, such as the unmodified Olden benchmark, or parts of OS kernels or the Emacs Lisp runtime.
The language itself: <https://crystal-lang.org/>. Crystal is heavily inspired by Ruby but with static typing and native compilation (via LLVM). To make up for not being dynamic like Ruby, it has powerful [global type inference](https://stackoverflow.com/a/4304513), meaning you're almost never *required* to explicitly specify types. The linked "Notes on..." page gives much more details.
Abstract: > A computer program describes not only the basic computations to be performed on input data, but also in which order and under which conditions to perform these computations. To express this sequencing of computations, programming language provide mechanisms called control structures. Since the "goto" jumps of early programming languages, many control structures have been deployed: conditionals, loops, procedures and functions, exceptions, iterators, coroutines, continuations… After an overview of these classic control structures and their historical context, the course develops a more modern approach of control viewed as an object that programs can manipulate, enabling programmers to define their own control structures. Started in the last century by early work on continuations and the associated control operators, this approach was recently renewed through the theory of algebraic effects and its applications to user-defined effects and effect handlers in languages such as OCaml 5.
Background: [What are denotational semantics, and what are they useful for?](https://langdev.stackexchange.com/questions/2019/what-are-denotational-semantics-and-what-are-they-useful-for) Also: [Operational and Denotational Semantics](https://hackmd.io/@alexhkurz/Hkf6BTL6P) > Denotational semantics assign meaning to a program (e.g. in untyped lambda calculus) by mapping the program into a self-contained domain model in some meta language (e.g. Scott domains). Traditionally, what is complicated about denotational semantics is not so much the *function* that defines them; rather it is to find a sound mathematical definition of the *semantic domain*, and a general methodology of doing so that scales to recursive types and hence general recursion, global mutable state, exceptions and concurrency[^1^](https://fixpt.de/blog/2024-09-23-total-denotational-semantics.html#fn1)[^2^](https://fixpt.de/blog/2024-09-23-total-denotational-semantics.html#fn2). > > In this post, I discuss a related issue: I argue that traditional Scott/Strachey denotational semantics are *partial* (in a precise sense), which means that > > 1. It is impossible to give a faithful, executable encoding of such a semantics in a programming language, and > 2. Internal details of the semantic domain inhibit high-level, equational reasonining about programs > > After exemplifying the problem, I will discuss *total* denotational semantics as a viable alternative, and how to define one using guarded recursion. > > I do not claim that any of these considerations are novel or indisputable, but I hope that they are helpful to some people who > > - know how to read Haskell > - like playing around with operational semantics and definitional interpreters > - wonder how denotational semantics can be executed in a programming language > - want to get excited about guarded recursion. > > I hope that this topic becomes more accessible to people with this background due to a focus on *computation*. > > I also hope that this post finds its way to a few semanticists who might provide a useful angle or have answers to the conjectures in the later parts of this post. > > If you are in a rush and just want to see how a total denotational semantics can be defined in Agda, have a look at [this gist](https://gist.github.com/sgraf812/b9c10d8386a5da7ffe014e9f1dd9bc83).
 gist.github.com
gist.github.com
This presents a method to reduce the overhead of the garbage collector, in a language with [multi-stage programming](https://en.wikipedia.org/wiki/Multi-stage_programming) (specifically [two-level type theory](https://andraskovacs.github.io/pdfs/2ltt.pdf)) using [**regions**](https://cyclone.thelanguage.org/wiki/Introduction%20to%20Regions/).
 surfingcomplexity.blog
surfingcomplexity.blog
Introduction: > Back in August, Murat Derimbas published a [blog post](https://muratbuffalo.blogspot.com/2024/08/linearizability-correctness-condition.html) about the [paper by Herlihy and Wing](https://dl.acm.org/doi/10.1145/78969.78972) that first introduced the concept of *linearizability*. When we move from sequential programs to concurrent ones, we need to [extend our concept of what "correct" means](https://surfingcomplexity.blog/2023/12/31/consistency/) to account for the fact that operations from different threads can overlap in time. Linearizability is the strongest consistency model for single-object systems, which means that it's the one that aligns closest to our intuitions. Other models are [weaker](https://surfingcomplexity.blog/2023/12/29/the-inherent-weirdness-of-system-behavior/) and, hence, will permit anomalies that violate human intuition about how systems should behave. > > Beyond introducing linearizability, one of the things that Herlihy and Wing do in this paper is provide an implementation of a linearizable queue whose correctness cannot be demonstrated using an approach known as *refinement mapping*. At the time the paper was published, it was believed that it was always possible to use refinement mapping to prove that one specification implemented another, and this paper motivated [Leslie Lamport](https://lamport.org/) and [Martín Abadi](https://research.google/people/abadi/) to propose the concept of *prophecy* *variables*. > > I have long been fascinated by the concept of prophecy variables, but when I learned about them, I still couldn't figure out how to use them to prove that the queue implementation in the Herlihy and Wing paper is linearizable. (I even [asked Leslie Lamport about it](https://www.youtube.com/watch?v=8nNJw-k8Ma0&t=15m) at the [2021 TLA+ conference](https://conf.tlapl.us/2021/)). > > Recently, Lamport published a book called [The Science of Concurrent Programs](https://lamport.azurewebsites.net/tla/science.pdf) that describes in detail how to use prophecy variables to do the refinement mapping for the queue in the Herlihy and Wing paper. Because the best way to learn something is to explain it, I wanted to write a blog post about this. > > In this post, I'm going to assume that readers have no prior knowledge about TLA+ or linearizability. What I want to do here is provide the reader with some intuition about the important concepts, enough to interest people to read further. There's a lot of conceptual ground to cover: to understand prophecy variables and why they're needed for the queue implementation in the Herlihy and Wing paper requires an understanding of *refinement mapping*. Understanding refinement mapping requires understanding the state-machine model that [TLA+](https://lamport.azurewebsites.net/tla/tla.html) uses for modeling programs and systems. We'll also need to cover what *linearizability* actually is. > > We'll going to start all of the way at the beginning: describing what it is that a program should do.
> ### Key Features > > - Multiple types (number, bool, datetime, string and error) > - Memory managed by user (no allocs) > - Iterator based interface > - Supporting variables > - Stateless > - Expressions can be compiled ([RPN](https://en.wikipedia.org/wiki/Reverse_Polish_notation) stack) > - Fully compile-time checked syntax > - Documented [grammar](https://github.com/torrentg/expr/blob/main/grammar.md) > - Standard C11 code > - No dependencies > > ### Examples > > ```c > # Numerical calculations > sin((-1 + 2) * PI) > > # Dates > datetrunc(now(), "day") > > # Strings > "hi " + upper("bob") + trim(" ! ") > > # Conditionals > ifelse(1 < 5 && length($alphabet) > 25, "case1", "case2") > > # Find the missing letter > replace($alphabet, substr($alphabet, 25 - random(0, length($alphabet)), 1), "") > ```
From homepage: > Hy (or "Hylang" for long) is a multi-paradigm general-purpose programming language in the [Lisp family](https://en.wikipedia.org/wiki/Lisp_(programming_language)). It's implemented as a kind of alternative syntax for Python. Compared to Python, Hy offers a variety of new features, generalizations, and syntactic simplifications, as would be expected of a Lisp. Compared to other Lisps, Hy provides direct access to Python's built-ins and third-party Python libraries, while allowing you to freely mix imperative, functional, and object-oriented styles of programming. [(More on "Why Hy?")](http://hylang.org/hy/doc/v1.0.0/whyhy) Some examples on the homepage: > Hy: > > ```hy > (defmacro do-while [test #* body] > `(do > ~@body > (while ~test > ~@body))) > > (setv x 0) > (do-while x > (print "Printed once.")) > ``` > > Python: > > ```python > x = 0 > print("Printed once.") > while x: > print("Printed once.") > ``` Interestingly programming.dev's Markdown renderer highlights \`\`\`hy code blocks. Maybe it knows the language ([highlight.js has it](https://github.com/highlightjs/highlight.js/blob/main/SUPPORTED_LANGUAGES.md)). Maybe it's using [Hybris](https://it-m-wikipedia-org.translate.goog/wiki/Hybris_(linguaggio_di_programmazione)?_x_tr_sl=it&_x_tr_tl=en&_x_tr_hl=en&_x_tr_pto=wapp) (another language that could get its own post, one of its extensions is `*.hy`). [GitHub](https://github.com/hylang/hy) [Online REPL](http://hylang.org/try-hy) [1.0 announcement](https://github.com/hylang/hy/discussions/2608)
 zserge.com
zserge.com
[GitHub (source code for all languages)](https://github.com/zserge/tinylangs), also linked above. - [Assembly](https://zserge.com/posts/langs-asm/) - [BASIC](https://zserge.com/posts/langs-basic/) - [Forth/MOUSE](https://zserge.com/posts/langs-mouse/) - [Lisp](https://zserge.com/posts/langs-lisp/) - [APL/K](https://zserge.com/posts/langs-apl/) - [PL/0](https://zserge.com/posts/langs-pl0/) The GitHub says "50 lines of code" but the largest example is 74 lines excluding whitespace and comments.
 adam-mcdaniel.github.io
adam-mcdaniel.github.io
> Dune is a shell designed for powerful scripting. Think of it as an unholy combination of `bash` and **Lisp**. > > You can do all the normal shell operations like piping, file redirection, and running programs. But, you also have access to a standard library and functional programming abstractions for various programming and sysadmin tasks! > > 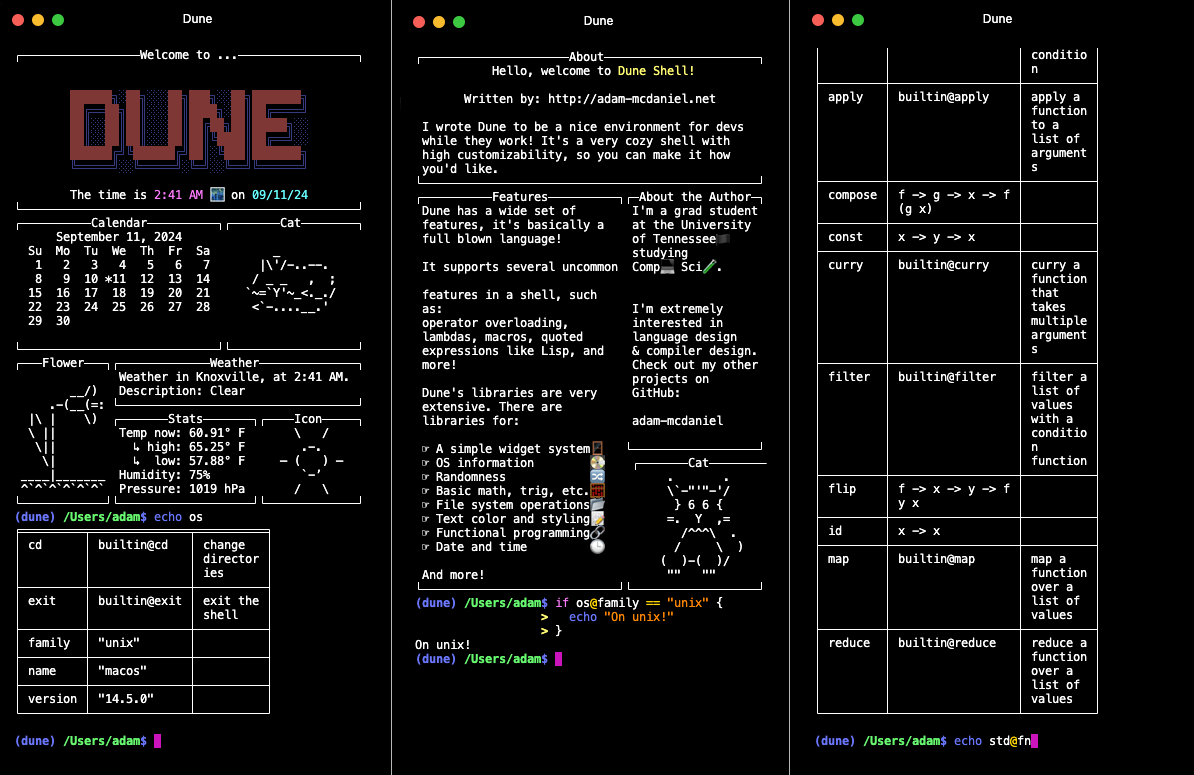
> Fennel is a programming language that brings together the simplicity, speed, and reach of [Lua](https://www.lua.org) with the flexibility of a [lisp syntax and macro system.](https://en.wikipedia.org/wiki/Lisp_(programming_language)) > > - **Full Lua compatibility:** Easily call any Lua function or library from Fennel and vice-versa. > - **Zero overhead:** Compiled code should be just as efficient as hand-written Lua. > - **Compile-time macros:** Ship compiled code with no runtime dependency on Fennel. > - **Embeddable:** Fennel is a one-file library as well as an executable. Embed it in other programs to support runtime extensibility and interactive development. > > Anywhere you can run Lua code, you can run Fennel code. Example: > ```lisp > ;; Sample: read the state of the keyboard and move the player accordingly > (local dirs {:up [0 -1] :down [0 1] :left [-1 0] :right [1 0]}) > > (each [key [dx dy] (pairs dirs)] > (when (love.keyboard.isDown key) > (let [[px py] player > x (+ px (* dx player.speed dt)) > y (+ py (* dy player.speed dt))] > (world:move player x y)))) > ```
Abstract: > We say that an imperative data structure is *snapshottable* or *supports snapshots* if we can efficiently capture its current state, and restore a previously captured state to become the current state again. This is useful, for example, to implement backtracking search processes that update the data structure during search. > > Inspired by a data structure proposed in 1978 by Baker, we present a *snapshottable store*, a bag of mutable references that supports snapshots. Instead of capturing and restoring an array, we can capture an arbitrary set of references (of any type) and restore all of them at once. This snapshottable store can be used as a building block to support snapshots for arbitrary data structures, by simply replacing all mutable references in the data structure by our store references. We present use-cases of a snapshottable store when implementing type-checkers and automated theorem provers. > > Our implementation is designed to provide a very low overhead over normal references, in the common case where the capture/restore operations are infrequent. Read and write in store references are essentially as fast as in plain references in most situations, thanks to a key optimisation we call *record elision*. In comparison, the common approach of replacing references by integer indices into a persistent map incurs a logarithmic overhead on reads and writes, and sophisticated algorithms typically impose much larger constant factors. > > The implementation, which is inspired by Baker's and the OCaml implementation of persistent arrays by Conchon and Filliâtre, is both fairly short and very hard to understand: it relies on shared mutable state in subtle ways. We provide a mechanized proof of correctness of its core using the Iris framework for the Coq proof assistant.
Back from break, I'm going to start posting regularly again. This is an interesting node-based visual programming environment with very cool graphics. It's written on Clojure but the various "cards" (nodes) can include SQL, R, DALL-E API calls, or anything else. > 

Excerpt: > This is a reconstruction -- extracted and very lightly edited -- of the "prehistory" of Rust development, when it was a personal project between 2006-2009 and, after late 2009, a Mozilla project conducted in private. > > The purposes of publishing this now are: > > - It might encourage someone with a hobby project to persevere > - It might be of interest to language or CS researchers someday > - It might settle some arguments / disputed historical claims Rust started being developed 18 years ago. This is how it looked until 14 years ago, where I believe the rest of development is on [rust-lang/rust](https://github.com/rust-lang/rust/commits/c2d4c1116f96463b8af222365d61d05bc42a78ac/?after=c2d4c1116f96463b8af222365d61d05bc42a78ac+34). The [first Rust program](https://github.com/graydon/rust-prehistory/blob/b0fd440798ab3cfb05c60a1a1bd2894e1618479e/test/foo.rs) looks completely different than the Rust we know today.
 firedancer-lang.com
firedancer-lang.com
[GitHub](https://github.com/fal-works/firedancer) > Haxe-based language for defining 2D shmups bullet-hell patterns. The [VM](https://github.com/fal-works/firedancer-vm) also runs in [Haxe](https://haxe.org/).
 blog.sigplan.org
blog.sigplan.org
> Soundly handling linearity requires special care in the presence of effect handlers, as the programmer may inadvertently compromise the integrity of a linear resource. For instance, duplicating a continuation that closes over a resource can lead to the internal state of the resource being corrupted or discarding the continuation can lead to resource leakage. Thus a naïve combination of linear resources and effect handlers yields an unsound system. ... > In the remainder of this blog post we describe a novel approach to rule out such soundness bugs by tracking *control-flow linearity*, a means to statically assure how often a continuation may be invoked which mediates between linear resources and effectful operations in order to ensure that effect handlers cannot violate linearity constraints on resources. We focus on our implementation in **Links**. The full technical details are available in our open access POPL'24 distinguished paper [Soundly Handling Linearity](https://dl.acm.org/doi/10.1145/3632896).
> Programming models like the Actor model and the Tuplespace model make great strides toward simplifying programs that communicate. However, a few key difficulties remain. > > The Syndicated Actor model addresses these difficulties. It is closely related to both Actors and Tuplespaces, but builds on a different underlying primitive: *eventually-consistent replication of state* among actors. Its design also draws on widely deployed but informal ideas like publish/subscribe messaging. For reference, [actors](https://en.wikipedia.org/wiki/Actor_model) and [tuple-spaces](https://en.m.wikipedia.org/wiki/Tuple_space) are means to implement concurrent programs. **Actors** are essentially tiny programs/processes that send (push) messages to each other, while a **tuple-space** is a shared repository of data ("tuples") that can be accessed (pulled) by different processes (e.g. actors). ... > A handful of Domain-Specific Language (DSL) constructs, together dubbed *Syndicate*, expose the primitives of the Syndicated Actor model, the features of dataspaces, and the concepts of conversational concurrency to the programmer in an ergonomic way. ... > To give some of the flavour of working with Syndicate DSL constructs, here's a program written in [JavaScript extended with Syndicate constructs](https://syndicate-lang.org/code/js/): > > ```javascript > function chat(initialNickname, sharedDataspace, stdin) { > spawn 'chat-client' { > field nickName = initialNickname; > > at sharedDataspace assert Present(this.nickname); > during sharedDataspace asserted Present($who) { > on start console.log(`${who} arrived`); > on stop console.log(`${who} left`); > on sharedDataspace message Says(who, $what) { > console.log(`${who}: ${what}`); > } > } > > on stdin message Line($text) { > if (text.startsWith('/nick ')) { > this.nickname = text.slice(6); > } else { > send sharedDataspace message Says(this.nickname, text); > } > } > } > } > ``` [Documentation](https://syndicate-lang.org/doc/) [Comparison with other programming models](https://syndicate-lang.org/about/syndicate-in-context/) [History](https://syndicate-lang.org/about/history/) [Author's thesis](https://syndicate-lang.org/papers/conversational-concurrency-201712310922.pdf)
Even though it's very unlikely to become popular (and if so, [it will probably take a while](https://en.wikipedia.org/wiki/Timeline_of_programming_languages)), there's a lot you learn from creating a programming language that applies to other areas of software development. Plus, it's fun!
armchair_progamer 2mo ago • 100%
The Tetris design system:
Write code, delete most of it, write more code, delete more of it, repeat until you have a towering abomination, ship to client.
The blog post is the author's impressions of Gleam after [it released version 1.4.0](https://gleam.run/news/supercharged-labels/). [Gleam](https://gleam.run/) is an upcoming language that is getting a lot of highly-ranked articles. It runs on the [Erlang virtual machine (BEAM)](https://en.wikipedia.org/wiki/BEAM_(Erlang_virtual_machine)), making it great for distributed programs and a competitor to [Elixir](https://elixir-lang.org/) and [Erlang (the language)](https://www.erlang.org/). It also compiles to [JavaScript](https://www.javascript.com/), making it a competitor to [TypeScript](https://www.typescriptlang.org/). But unlike Elixir, Erlang, and TypeScript, it's *strongly* typed (not just gradually typed). It has "functional" concepts like algebraic data types, immutable values, and first-class functions. The syntax is modeled after [Rust](https://www.rust-lang.org/) and its [tutorial](https://tour.gleam.run/) is modeled after [Go's](https://go.dev/tour/). Lastly, it has a very large community.
armchair_progamer 2mo ago • 99%
But is it rewritten in Rust?

armchair_progamer 3mo ago • 100%
“I’ve got 10 years of googling experience”.
“Sorry, we only accept candidates with 12 years of googling experience”.
armchair_progamer 4mo ago • 100%
armchair_progamer 5mo ago • 100%
Author's comment on lobste.rs:
Yes it’s embeddable. There’s a C ABI compatible API similar to what lua provides.
armchair_progamer 5mo ago • 91%
C++’s mascot is an obese sick rat with a missing foot*, because it has 1000+ line compiler errors (the stress makes you overeat and damages your immune system) and footguns.
EDIT: Source (I didn't make up the C++ part)


armchair_progamer 5mo ago • 100%
I could understand method = associated function whose first parameter is named self, so it can be called like self.foo(…). This would mean functions like Vec::new aren’t methods. But the author’s requirement also excludes functions that take generic arguments like Extend::extend.
However, even the above definition gives old terminology new meaning. In traditionally OOP languages, all functions in a class are considered methods, those only callable from an instance are “instance methods”, while the others are “static methods”. So translating OOP terminology into Rust, all associated functions are still considered methods, and those with/without method call syntax are instance/static methods.
Unfortunately I think that some people misuse “method” to only refer to “instance method”, even in the OOP languages, so to be 100% unambiguous the terms have to be:
- Associated function: function in an
implblock. - Static method: associated function whose first argument isn’t
self(even if it takesSelfunder a different name, likeBox::leak). - Instance method: associated function whose first argument is
self, so it can be called likeself.foo(…). - Object-safe method: a method callable from a trait object.
armchair_progamer 6mo ago • 100%
Java the language, in human form.
armchair_progamer 6mo ago • 100%
I find writing the parser by hand (recursive descent) to be easiest. Sometimes I use a lexer generator, or if there isn’t a good one (idk for Scheme), write the lexer by hand as well. Define a few helper functions and macros to remove most of the boilerplate (you really benefit from Scheme here), and you almost end up writing the rules out directly.
Yes, you need to manually implement choice and figure out what/when to lookahead. Yes, the final parser won’t be as readable as a BNF specification. But I find writing a hand-rolled parser generator for most grammars, even with the manual choice and lookahead, is surprisingly easy and fast.
The problem with parser generators is that, when they work they work well, but when they don’t work (fail to generate, the generated parser tries to parse the wrong node, the generated parser is very inefficient) it can be really hard to figure out why. A hand-rolled parser is much easier to debug, so when your grammar inevitably has problems, it ends up taking less time in total to go from spec to working hand-rolled vs. spec to working parser-generator-generated.
The hand-rolled rules may look something like (with user-defined macros and functions define-parse, parse, peek, next, and some simple rules like con-id and name-id as individual tokens):
; pattern ::= [ con-id ] factor "begin" expr-list "end"
(define-parse pattern
(mk-pattern
(if (con-id? (peek)) (next))
(parse factor)
(do (parse “begin”) (parse expr-list) (parse “end”))))
; factor ::= name-id
; | symbol-literal
; | long-name-id
; | numeric-literal
; | text-literal
; | list-literal
; | function-lambda
; | tacit-arg
; | '(' expr ')'
(define-parse factor
(case (peek)
[name-id? (if (= “.” (peek2)) (mk-long-name-id …) (next))]
[literal? (next)]
…))
Since you’re using Scheme, you can almost certainly optimize the above to reduce even more boilerplate.
Regarding LLMs: if you start to write the parser with the EBNF comments above each rule like above, you can paste the EBNF in and Copilot will generate rules for you. Alternatively, you can feed a couple EBNF/code examples to ChatGPT and ask it to generate more.
In both cases the AI will probably make mistakes on tricky cases, but that’s practically inevitable. An LLM implemented in an error-proof code synthesis engine would be a breakthrough; and while there are techniques like fine-tuning, I suspect they wouldn’t improve the accuracy much, and certainly would amount to more effort in total (in fact most LLM “applications” are just a custom prompt on plain ChatGPT or another baseline model).
armchair_progamer 6mo ago • 100%

armchair_progamer 6mo ago • 100%
My general take:
A codebase with scalable architecture is one that stays malleable even when it grows large and the people working on it change. At least relative to a codebase without scalable architecture, which devolves into "spaghetti code", where nobody knows what the code does or where the behaviors are implemented, and small changes break seemingly-unrelated things.
Programming language isn't the sole determinant of a codebase's scalability, especially if the language has all the general-purpose features one would expect nowadays (e.g. Java, C++, Haskell, Rust, TypeScript). But it's a major contributor. A "non-scalable" language makes spaghetti design decisions too easy and scalable design decisions overly convoluted and verbose. A scalable language does the opposite, nudging developers towards building scalable software automatically, at least relative to a "non-scalable" language and when the software already has a scalable foundation.
armchair_progamer 6mo ago • 96%
public class AbstractBeanVisitorStrategyFactoryBuilderIteratorAdapterProviderObserverGeneratorDecorator {
// boilerplate goes here
}
armchair_progamer 7mo ago • 100%

armchair_progamer 7mo ago • 100%
“You're going into Orbit, you stupid mutt.”
armchair_progamer 7mo ago • 100%
I believe the answer is yes, except that we’re talking about languages with currying, and those can’t represent a zero argument function without the “computation” kind (remember: all functions are Arg -> Ret, and a multi-argument function is just Arg1 -> (Arg2 -> Ret)). In the linked article, all functions are in fact “computations” (the two variants of CompType are Thunk ValType and Fun ValType CompType). The author also describes computations as “a way to add side-effects to values”, and the equivalent in an imperative language to “a value which produces side-effects when read” is either a zero-argument function (getXYZ()), or a “getter” which is just syntax sugar for a zero-argument function.
The other reason may be that it’s easier in an IR to represent computations as intrinsic types vs. zero-argument closures. Except if all functions are computations, then your “computation” type is already your closure type. So the difference is again only if you’re writing an IR for a language with currying: without CBPV you could just represent closures as things that take one argument, but CBPV permits zero-argument closures.
armchair_progamer 8mo ago • 100%
Go as a backend language isn’t super unusual, there’s at least one other project (https://borgo-lang.github.io) which chosen it. And there are many languages which compile to JavaScript or C, but Go strikes a balance between being faster than JavaScript but having memory management vs. C.
I don’t think panics revealing the Go backend are much of an issue, because true “panics” that aren’t handled by the language itself are always bad. If you compile to LLVM, you must implement your own debug symbols to get nice-looking stack traces and line-by-line debugging like C and Rust, otherwise debugging is impossible and crashes show you raw assembly. Even in Java or JavaScript, core dumps are hard to debug, ugly, and leak internal details; the reason these languages have nice exceptions, is because they implement exceptions and detect errors on their own before they become “panics”, so that when a program crashes in java (like tries to dereference null) it doesn’t crash the JVM. Golang’s backtrace will probably be much nicer than the default of C or LLVM, and you may be able to implement a system like Java which catches most errors and gives your own stacktrace beforehand.
Elm’s kernel controversy is also something completely different. The problem with Elm is that the language maintainers explicitly prevented people from writing FFI to/from JavaScript except in the maintainers’ own packages, after allowing this feature for a while, so many old packages broke and were unfixable. And there were more issues: the language itself was very limited (meaning JS FFI was essential) and the maintainers’ responses were concerning (see “Why I’m leaving Elm”). Even Rust has features that are only accessible to the standard library and compiler (“nightly”), but they have a mechanism to let you use them if you really want, and none of them are essential like Elm-to-JS FFI, so most people don’t care. Basically, as long as you don’t become very popular and make a massively inconvenient, backwards-incompatible change for purely design reasons, you won’t have this issue: it’s not even “you have to implement Go FFI”, not even “if you do implement Go FFI, don’t restrict it to your own code”, it’s “don’t implement Go FFI and allow it everywhere, become very popular, then suddenly restrict it to your own code with no decent alternatives”.
armchair_progamer 8mo ago • 100%
https://github.com/cell-lang/example-online-forum
https://github.com/cell-lang/example-imdb
A more complex example, the compiler itself is written in Cell: https://github.com/cell-lang/compiler/tree/master
The getting started page has download links for the code generators (C++, Java, and C#) and setup instructions.